
とある処理を書く方法が色々ある場合は、どれを選んだ方がもっとも良いかと悩ましくなります。こういう場合は、コードの読みやすさやコードの長さ、予想される問題のようなさまざまな観点からそれぞれの方式を比較してどれを選ぶか判断することになりますね。ただ、このような観点から判断するのは多くの場合「書き方が全く違う」場合に有効であって、そもそも似たようなコードを書くことになる場合は他の観点からも考える必要があります。ほんの少しだけ違うから、見た目だけでは違いがわからない場合。こういう時はそのAPIの内部、メカニズムからちゃんと考えて選ぶ必要がありますね。
そういう意味で、今回はKotlinのCollectionの処理に使える方法の二つ、「Collectionのoperation直接使う」場合と「Sequenceに変換してから処理する」場合の違いに関して述べたいと思います。
処理方式の違い
Javaでは、Collectionの要素を持って処理をする方法は色々とありますが、大きく分けて1.8以前の方法(forやwhileなどを利用したループ)と1.8以降の方法(Streamを使った方法)があると言ってもいいのではないかと思います。この二つの方法はそもそもベースとなっているパラダイムそのものが違うので、コードを書くスタイルから大きく違います。例えば同じ処理をしたい場合でも、以下のコードで確認できるように、見た目が完全に違います。
// forループの場合
List<String> filterEven() {
List<Integer> list = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<String> result = new ArrayList<>();
for (Integer i : list) {
if (i % 2 == 0) {
result.add(i.toString());
if (result.size() == 3) {
break;
}
}
}
return result;
}
// Streamを使う場合
List<String> filterEvenStream() {
return List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
.stream()
.filter(i -> i % 2 == 0)
.map(i -> i.toString())
.limit(3)
.collect(Collectors.toList());
}
Streamを使った処理の場合はoperationを積み重ねて行く形をしていますが、これは現代の関数型プログラミングに対応している言語ならどれも持っているAPIといえます。例えばKotlin, 公式的には呼び方が色々あるようですが、一部ではFunctional functionという名で呼ばれているようで、今回はこの操作方式、Functional functionについて述べたいと思います。
KotlinではCollectionでもこのようなopreationがあり、Kotlin版のStreamとも言えるSequenceでも同様の操作できるようになっています。また、JavaのStreamをそのまま使うこともできるので、Functional functionを使った処理は三つがあるといえますね。それぞれの使い方もあまり変わりません。なので以下のようなコードで同じ処理ができますが、それが帰って悩ましくなるところでもあります。「どれを使ったらいい?」とですね。例えば同じ処理をしたい場合でも、Kotlinでは以下のように色々な方法を使えます。
// Collectionの場合
fun filterEven(): List<String> = listOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).filter { it %2 == 0 }.map { it.toString() }.take(3)
// Sequenceを使う場合
fun filterEvenSequence: List<String> = listOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).asSequence().filter { it %2 == 0 }.map { it.toString() }.take(3).toList()
// JavaのStream APIを使う場合
fun filterEvenStream(): List<String> = listOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).stream().filter { it %2 == 0 }.map { it.toString() }.limit(3).collect(Collectors.toList())
上記のコードは見た目ではあまり違いがわからないですね。処理やロジックが大きく変わる訳でもありません。使い方があまり変わらなく、結果としても同じようなものを期待できるとしたら、やはり次に気にすべきは「性能」ではないかと思います。特にCollectionよりもSequenceの方がより性能がいいという話もありますので、それならなるべくSequenceを使った方が絶対良いはずですね。
しかし、それを事実と受け止めるとしたら、いくつかの疑問が残ります。常にSequenceの方が性能で有利だとしたら、なぜCollectionからFunctional functionを呼び出す時は内部でSequenceに変換するようにするのでなく、わざわざasSequence()を呼び出して明示的な変換をさせるのでしょうか?もしくはなぜCollectionでもFunctional functionを呼び出せるようにしているのでしょうか?これはつまり、SequenceがCollectionよりも性能がよくなるのは「とある条件下に限る」ということではないでしょうか。なので、今回は主に性能の観点から、CollectionとSequenceの違いについて述べましょう。
Lazy evaluation
KotlinのSequenceは、元々JavaのStreamと同じ名前になる予定だったそうです。これはただの偶然ではなく、実際の処理もStreamに似ているからです。何が似ているかというと、Lazy evaluationという概念です。これは簡単に言いますと、「なるべく処理を遅延させる = 必要とされるまでは処理をしない」ということですね。そして多くの場合、Sequenceを使うとこのLazy evaluationのおかげで性能がよくなるという話があります。これはつまり、Sequenceは処理を遅延することでCollectionより良い性能を期待できる、ということになるでしょう。
しかし、単純に処理を遅延させることががなぜ性能を向上させる事になるのか、すぐに納得は行きません。まず、ループ処理の中で「必要によって処理をするかどうかを決定する」という概念がピンと来ないですね。我々が認識しているループ処理とは、対象となるデータモデルの全要素を巡回しながら処理をするという意味ですので。
だからSequenceを使った方が性能がよくなると言っても、パフォーマンスはさまざまな要素によって劣化も向上もするものなので、その話だけを信じて全ての処理をSequenceに変えるということは危ないです。そもそもSequenceがそんなに良いものであれば、全てのIterableなオブジェクトをなぜSequenceとして処理しないか、という疑問も湧いてきますね。なので、まずはCollectionとSequenceでFunctional functionがどう違うか、コードどそれを実行した結果で説明したいと思います。
Eager evaluationのCollection
CollectionでのFunctional functionは、Eager evalutionと言われています。これはLazy evaluationの逆で、必要とされてなくてもとりあえず処理を行っておくということです。こうする場合期待できることは、メモリ上にすでに処理の結果が残っていて、複数回呼ばれた場合はそのキャッシュを使うことができるということですね。
Eager evaluationだと、Functional functionが呼ばれるたび、その全要素に対しての処理をまず行うことになります。例えば、以下のような処理を書いたとしましょう。onEach()は処理の流れを視覚化するためのものです。
listOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
.filter { it %2 == 0 }
.onEach { println("Found even: $it") }
.map { it.toString() }
.onEach { println("Now $it is String") }
.take(3)
.onEach { println("$it has taken") }
このコードを実行した結果は以下の通りです。
Found even: 2
Found even: 4
Found even: 6
Found even: 8
Found even: 10
Now 2 is String
Now 4 is String
Now 6 is String
Now 8 is String
Now 10 is String
2 has taken
4 has taken
6 has taken
つまり、CollectionでのFunctional functionでは以下のような順で処理します。
- Listからfilterのpredicateに当てはまる要素を探し、その結果でListを作る
- filterされたListの要素をmapし、その結果でListを作る
- mapされたListの要素からtakeする
これを絵で表現すると以下の通りです。
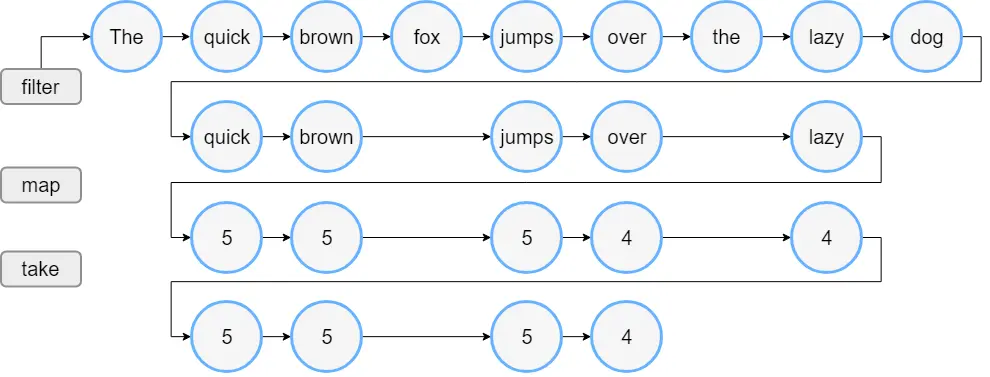 出典:Kotlin公式ドキュメント - Sequences
出典:Kotlin公式ドキュメント - Sequences
Collectionのopreation
Collectionでの処理は上記の通りですが、実装としてはどうでしょうか。ここではCollectionでのmap()のコードを見ていきたいと思います。コードとしては以下のようになっています。
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
mapTo()という関数に、元のCollectionのサイズで新しくインスタンスを作成したArrayListとLambdaを渡しています。ちなみにcollectionSizeOrDefault()という関数は、以下のような実装となっています。Collectionである場合はそのサイズを、そうでない場合(Sequenceなど)はデフォルトとして10のサイズを持つListになるということがわかりますね。
internal fun <T> Iterable<T>.collectionSizeOrDefault(default: Int): Int = if (this is Collection<*>) this.size else default
また、mapTo()という関数の中では、元のCollectionをループしながら新しいListにLambdaの実行結果を追加するという実装となっています。実際のコードは、以下の通りです。
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapTo(destination: C, transform: (T) -> R): C {
for (item in this)
destination.add(transform(item))
return destination
}
ここでわかるのは、一つのFunctional functionが呼ばれるたびにListに対するループが発生し、さらに新しいListを作ることになるということです。なので上記のサンプルコードの場合だとループは6回、Listの作成は4回であるといえます。onEach()を除外するとしてもループは3回なので、かなり多い印象ですね。
ここで考えられるものは、「Sequenceの方が性能がいい」という話は、Sequenceを使った場合にこのようなループ回数やListの作成を減らせられるということになるのではないか、ということですね。Sequenceではどんな処理をしていて、実際にこのようなループやListを作る回数などを減らしているということでしょうか。同じ処理を書いた場合にSequenceではどのようなことが起きるかを見ていきましょう。
Lazy evaluationのSequence
Collectionは、asSequence()を呼び出すことで簡単にSequenceによる処理に変換することができます。ただ、このコードを実際に走らせるためにはJavaのStreamと同じく終端処理が必要となるのがポイントです。これも「必要とされるまでは実際の処理を行わない」Lazy evaluationの特徴といえます。例えば以下のようなコードを書いたとしましょう。
listOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
.asSequence() // Sequenceに変換
.filter { it %2 == 0 }
.onEach { println("Found even: $it") }
.map { it.toString() }
.onEach { println("Now $it is String") }
.take(3)
.onEach { println("$it has taken") }
.toList() // Collectionに再変換(終端処理で処理を走らせる)
このコードを実行した結果は以下の通りです。Collectionの場合と結果は同じであるものの、処理の順番が変わっていることを確認できます。
Found even: 2
Now 2 is String
2 has taken
Found even: 4
Now 4 is String
4 has taken
Found even: 6
Now 6 is String
6 has taken
ここでわかるのは、そもそも8と10に対しての処理は行われてないということです。これはCollectionで全要素に対して一つのFunctional functionの処理が終わったあと、次のFunctional functionが実行される構造に対して、Sequenceは一つの要素に対しての全ての処理が終わったあと次の要素に対して同じ処理を繰り返しているということです。言葉で表現すると複雑ですが、以下のような順になっているということです。
- Listの要素にfilterを当てる
- 要素がfilterのpredicateに当てはまるものなら次の処理に移行する
- filterされた要素をmapする
- mapされた要素をtakeする
- 次の要素に対して同じ処理を繰り返す
これを絵で表現すると以下の通りです。
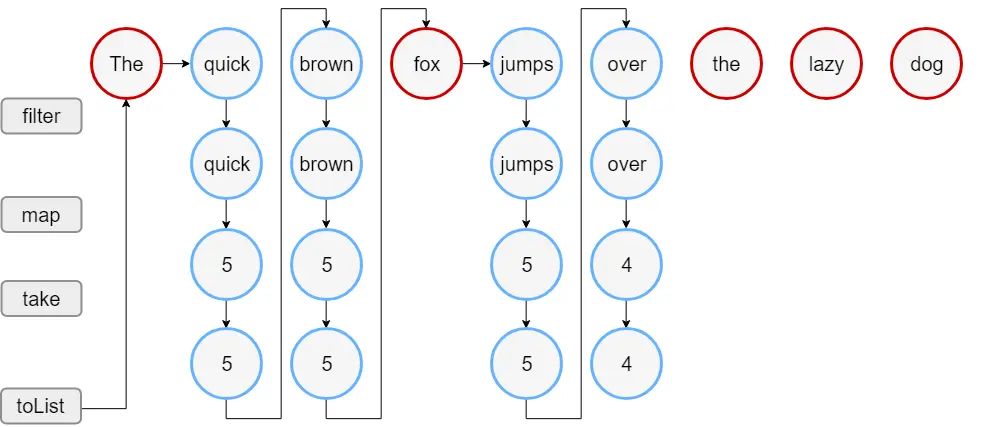 出典:Kotlin公式ドキュメント - Sequences
出典:Kotlin公式ドキュメント - Sequences
処理の順番や仕組みが違うので、Collectionの時とは実装もかなり違うだろうと予想ができますね。では、こちらの実装を見ていきましょう。
Sequenceでのoperation
Collectionと同じく、Sequenceのmap()の実装を覗いてみましょう。先程のコードでSequenceのmap()は中間処理であり、新しいCollectionを作り出すわけではないということはわかりました。実装を見ると、以下のようになっていて、処理結果が反映されたSequenceを返しているのがわかります。
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
ただ、内部でTransformingSequenceという新しいSequenceのインスタンスを作成しているのがわかりますね。このクラスの実装は以下の通りです。ここでループごとにLambdaの実行が行われていますね。
internal class TransformingSequence<T, R>
constructor(private val sequence: Sequence<T>, private val transformer: (T) -> R) : Sequence<R> {
override fun iterator(): Iterator<R> = object : Iterator<R> {
val iterator = sequence.iterator()
override fun next(): R {
return transformer(iterator.next())
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
internal fun <E> flatten(iterator: (R) -> Iterator<E>): Sequence<E> {
return FlatteningSequence<T, R, E>(sequence, transformer, iterator)
}
}
以上のコードの実行結果と実装でわかるように、Sequenceを使う場合は一つの要素を単位として処理を行っていくので、CollectionでFunctional functionを使う場合に発生し得る不要な処理(毎回Listを生成する、前要素に対してmapを行うなど)を減らせると期待できます。なので元のCollectionが大きい場合やoperationが多い場合はSequenceの方がより良いように見えます。
ただ、性能の観点で考えると、CollectionとSequenceの違いはもう一つ考慮すべきところがあります。それはデータ構造の違いです。
Stateless
JavaのStreamでもそうでしたが、Sequenceは状態(State)を持たないのが特徴です。ここで状態を持たないということは、持っている要素の数や順番などに対しての情報がないということを意味します。なぜかというと、SequenceがIteratorに基づいているものだからです。そしてそれが原因で、処理の種類によってCollectionよりも性能は劣る可能性もまたあります。
先に使っていたサンプルコードを持って考えてみましょう。サンプルコードでは、Sequenceの終端処理としてListを返すためにtoList()を呼び出していました。これは、「状態を持たない」ものから「状態を持つ」ものに変換することですね。簡単なやり方としては、MutableなListを作って、全要素を一つづつadd()していく方法があるでしょう。実際はどうでしょうか?まずはtoList()のコードをみてみましょう。以下がその実装です。
public fun <T> Sequence<T>.toList(): List<T> {
return this.toMutableList().optimizeReadOnlyList()
}
まずMutableなListに変換して、さらに読み込み専用(Immutable)のListに変換しているように見えます。さらにMutable Listに変えているところの実装をみてみましょう。
public fun <T> Sequence<T>.toMutableList(): MutableList<T> {
return toCollection(ArrayList<T>())
}
ArrayListのインスタンスを作って、それをtoCollection()に渡していますね。ここでtoCollection()はSequenceをCollectionに帰る時の共通処理で、型を指定にするため引数にListを渡しているようです。さらにtoCollection()の実装をみていきましょう。
public fun <T, C : MutableCollection<in T>> Sequence<T>.toCollection(destination: C): C {
for (item in this) {
destination.add(item)
}
return destination
}
ここまでたどり着いてわかったのは、やはりSequenceの要素を一つ一つListの中に入れているということですね。ただ、単純な処理ではありますが、ここでは「Listに要素を足していく」ということ自体に注目する必要があります。
先に述べた通り、Sequenceは自分が持つ要素の数をわからないので、Listのインスタンスを作る時はサイズを「仮定」して処理するしかないです。そして基本的にMutableなListでは、現在のサイズよりも多くの要素を追加する必要がある時、内部のArrayより大きいサイズのArrayを新しく作り、そこに要素をコピーしていくことを繰り返します。そしてこれを全要素が揃うまで繰り返していきますね。ということは、Sequenceの要素が多ければ多いほどArrayのインタンス作成とコピーが多くなるということになります。
そしてコピーが全部終わった場合、実際の要素数よりArrayのサイズが大きい場合もありますね。その場合、メモリを無駄に使うだけでなく、実際のサイズもわからなくなるので、サイズを要素数に合わせて再調整する必要があります。toList()の実装で最後にoptimizeReadOnlyList()を呼び出しているのは、おそらくその理由でしょう。optimizeReadOnlyList()の実装は以下の通りです。やはりサイズを再調整していますね。
internal fun <T> List<T>.optimizeReadOnlyList() = when (size) {
0 -> emptyList()
1 -> listOf(this[0])
else -> this
}
これでわかるように、Sequenceを使って処理したあと、Collectionにまとめるなら要素数が多ければ多いほどCollectionよりも性能が劣化する可能性は確かに存在します。CollectionでFunctional functionを呼び出す際にListを作るとしても、すでに要素数はわかっているので、Listのサイズが合わないためのArrayの生成とコピーの処理は不要ですね。なのでCollectionとSequenceのどちらを選ぶかの問題はFunctional functionを呼び出す回数や処理の種類だけでなく、要素の数まで考える必要がありそうです。
ただ、要素数が多い場合でも、終端処理の種類によってはSequenceの方が有利になる可能性もなくはないです。例えばforEach()やonEach()など、個別の要素に対して処理を行うだけの場合は依然としてSequenceの方で良い性能を期待できるでしょう。
要素数が多い場合に性能に影響する処理としてもう一つ考えられるのは、Sequenceを使う場合でも呼び出せるFunctional functionの中で明らかに「状態を必要とする」ものがあるということです。例えば以下の一覧のようなものです。
- どんな要素が含まれているかわかる必要がある
distinct()average()min()max()take()
- 要素の順番をわかる必要がある
indexOf()mapIndexed()flatMapIndexed()elementAt()filterIndexed()foldIndexed()forEachIndexed()reduceIndexed()scanIndexed()
これらの処理をSequenceではどうしているのでしょうか。まずはその実装を覗いてみる必要がありそうですね。ここではsort()の方をみていきたいと思います。実装は以下のようになっています。
public fun <T : Comparable<T>> Sequence<T>.sorted(): Sequence<T> {
return object : Sequence<T> {
override fun iterator(): Iterator<T> {
val sortedList = this@sorted.toMutableList()
sortedList.sort()
return sortedList.iterator()
}
}
}
単純ですが、Sequenceを一度Listに変換してsortした後、またSequenceに変えて返していますね。ここでListに変えるために呼び出している関数はtoMutableList()なので、結局toList()を呼び出す場合と同じようなことが起きるということです。なので、状態を必要とする操作の場合は要素数が多ければ多いほど性能はCollectionより劣化しやすい、ということがわかります。
ただ、逆に状態が必要にならない場合は、Collectionと違って中間結果のListを作成しなくなるので、依然としてSequenceが良い性能を見せるだろうと思えます。
最後に
だいぶ話が長くなりましたが、性能の観点でどれを選ぶべきか、という話の結論としては、「どんな処理をするか」によるということになりますね。簡単に整理すると、以下のようになるかと思います。
| 条件 | おすすめ |
|---|---|
| 処理が複雑 | Sequence |
| 処理した結果としてCollectionが必要 | Collection |
| ループするだけ | Sequence |
| 処理に状態が必要 | Collection |
| 要素数が多い | Sequence |
| 要素数が少ない | Collection |
もちろんこれらの条件が複数ある場合も十分考えられるので、必要な処理が何かをよく考えてどちらを使うかを慎重に考える必要がありそうです。多くの場合とりあえずCollectionを使うという方針だとしても特に問題はなさそうな気はしますが…
この度はKotlinにおいてのSequenceを紹介しましたが、実はイラストを含めてわかりやすく説明しているいつSequenceを使うべきかという良い記事があるので、Sequenceについてより深く理解したい方にはこちらを参考した方が良さそうな気がします。
また、ここではKotlinのAPIでの処理のみを紹介しましたが、JavaのStreamを使う場合、Sequenceと違ってparallelStream()を呼び出すことができます。なので並列で処理しても良い場合には、CollectionとSequenceのみでなく、Streamを使うことを検討するのもありですね。
では、また!