
Java 17がリリースされてから約2年、今月にはJava 21がリリースされます。まだ案件によっては1.7など古いバージョンを使っている場合も多いと思いますが、21は新しいLTSなので、今後新しいプロジェクトを始めるときは採用を検討するのも良いかもしれません。そこで今回はJava 21で何が変わったのかをざっくりとまとめてみました。
今回の記事はJava 17からの変化について述べているので、Java 11から17までの変化については前回のポストを参照してください。
言語スペック
String Templates (Preview)
Kotlinのような言語にはいわゆるString Interpolationという機能があります。これは文字列の中に変数を埋め込むことができる機能ですね。例えばxとyという変数があったとして、それをStringに埋め込むときにKotlinだと以下のように書くことができます。
val s = "$x plus $y equals ${x + y}"
これをJavaで実現するためには以下のように書くことになります。
// String concatenation
String s = x + " plus " + y + " equals " + (x + y);
// StringBuilder
String s = new StringBuilder()
.append(x)
.append(" plus ")
.append(y)
.append(" equals ")
.append(x + y)
.toString();
// String.format
String s = String.format("%2$d plus %1$d equals %3$d", x, y, x + y);
String t = "%2$d plus %1$d equals %3$d".formatted(x, y, x + y);
// MessageFormat
MessageFormat mf = new MessageFormat("{0} plus {1} equals {2}");
String s = mf.format(x, y, x + y);
これらの方法はどれも冗長で、可読性が低いです。そこでJava 21ではString Templatesという機能が追加されました。これは文字列の中に変数を埋め込むことができる機能です。なので、Javaでももっと簡単な方法でStringを作成することができるようになりました。
ただ、String InterpolationにはSQL Injectionのような問題があるので、Javaでは別のアプローチを取りました。これは文字列の中に変数を埋め込むのではなく、文字列の中に変数を埋め込むためのテンプレートをまず作成して、それを使って文字列を作成するという方法になっています。なのでコード以下のようになります。
// STRを使う場合
String name = "Joan";
String info = STR."My name is \{name}"; // My name is Joan
// RAWを使う場合
String name = "Joan";
StringTemplate st = RAW."My name is \{name}";
String info = STR.process(st); // My name is Joan
STRやRAWはStringTemplateのインスタンスをまず作るようになっていますが、このStringTemplateのインスタンスにはfragmentsというフィールドとvaluesという配列があります。fragmentsは文字列の中に変数があるところを空文字列に置き換えたものの配列で、valuesは変数の値の配列です。なので、変数を埋め込んだ結果の文字列だけでなく実際与えられた変数の値も取得することができます。
int x = 10, y = 20;
StringTemplate st = RAW."\{x} plus \{y} equals \{x + y}";
String s = st.toString(); // StringTemplate{ fragments = [ "", " plus ", " equals ", "" ], values = [10, 20, 30] }
また、StringTemplateにはProcessorというInterfaceがあり、Functional Interfaceとして独自の実装をすることも可能です。
// Processor Interface
public interface StringTemplate {
@FunctionalInterface
public interface Processor<R, E extends Throwable> {
R process(StringTemplate st) throws E;
}
}
var INTER = StringTemplate.Processor.of(StringTemplate::interpolate);
String s = INTER."\{x} plus \{y} equals \{x + y}";
まだPreviewなので、このような使い方は今後変わる可能性がありますが、かなり面白いアプローチなので今後の動向に注目したい機能でした。
Sequenced Collections
JavaのCollectionの場合、種類によって最後の要素を取るためには色々書き方が変わったり、冗長になったりしますね。例えば、最初の要素と最後の要素を取る場合Collecitonの種類によって以下のようになります。
// List
var firstOnList = list.get(0);
var lastOnList = list.get(list.size() - 1);
// Deque
var firstOnDeque = deque.getFirst();
var lastOnDeque = deque.getLast();
// SortedSet
var firstOnSortedSet = sortedSet.first();
var lastOnSortedSet = sortedSet.last();
// LinkedHashSet
var firstOnLinkedHashSet = linkedHashSet.iterator().next();
var lastOnLinkedHashSet = linkedHashSet.stream().reduce((first, second) -> second).orElse(null);
また、ループを逆順にする場合もコードは冗長になったり、使い勝手が悪く感じられる場合もあります。例えば以下のコードを見ると、やろうとしていることは一緒なのに、コードが全然違うということがわかります。
// NavigableSet with descendingSet
for (var e: navigableSet.descendingSet()) {
process(e);
}
// Deque with reverse Iterator
for (var it = deque.descendingIterator(); it.hasNext(); ) {
var e = it.next();
process(e);
}
// List with reverse ListIterator
for (var it = list.listIterator(list.size()); it.hasPrevious(); ) {
var e = it.previous();
process(e);
}
また実装クラスによっては要素の順番が保持されるCollectionからそうでないものにダウングレードされるケースもあります。例えばLinkedHashSetをCollections::unmodifiableSetでラップすると、LinkedHashSetの順番が失われることになります。
そこでJava 21ではSequencedCollectionおよびSequencedSetというInterfaceを追加して、上記の問題を解決します。これらInterfaceは以下のようなメソッドを提供します。
interface SequencedCollection<E> extends Collection<E> {
// new method
SequencedCollection<E> reversed();
// methods promoted from Deque
void addFirst(E);
void addLast(E);
E getFirst();
E getLast();
E removeFirst();
E removeLast();
}
interface SequencedSet<E> extends Set<E>, SequencedCollection<E> {
SequencedSet<E> reversed(); // covariant override
}
またMapにおいてもSequencedMapというInterfaceが追加されていて、以下のようなメソッドを提供します。
interface SequencedMap<K,V> extends Map<K,V> {
// new methods
SequencedMap<K,V> reversed();
SequencedSet<K> sequencedKeySet();
SequencedCollection<V> sequencedValues();
SequencedSet<Entry<K,V>> sequencedEntrySet();
V putFirst(K, V);
V putLast(K, V);
// methods promoted from NavigableMap
Entry<K, V> firstEntry();
Entry<K, V> lastEntry();
Entry<K, V> pollFirstEntry();
Entry<K, V> pollLastEntry();
}
これらの新しいInterfaceが追加されることで、Collection全体の継承関係が以下のように変更されました。
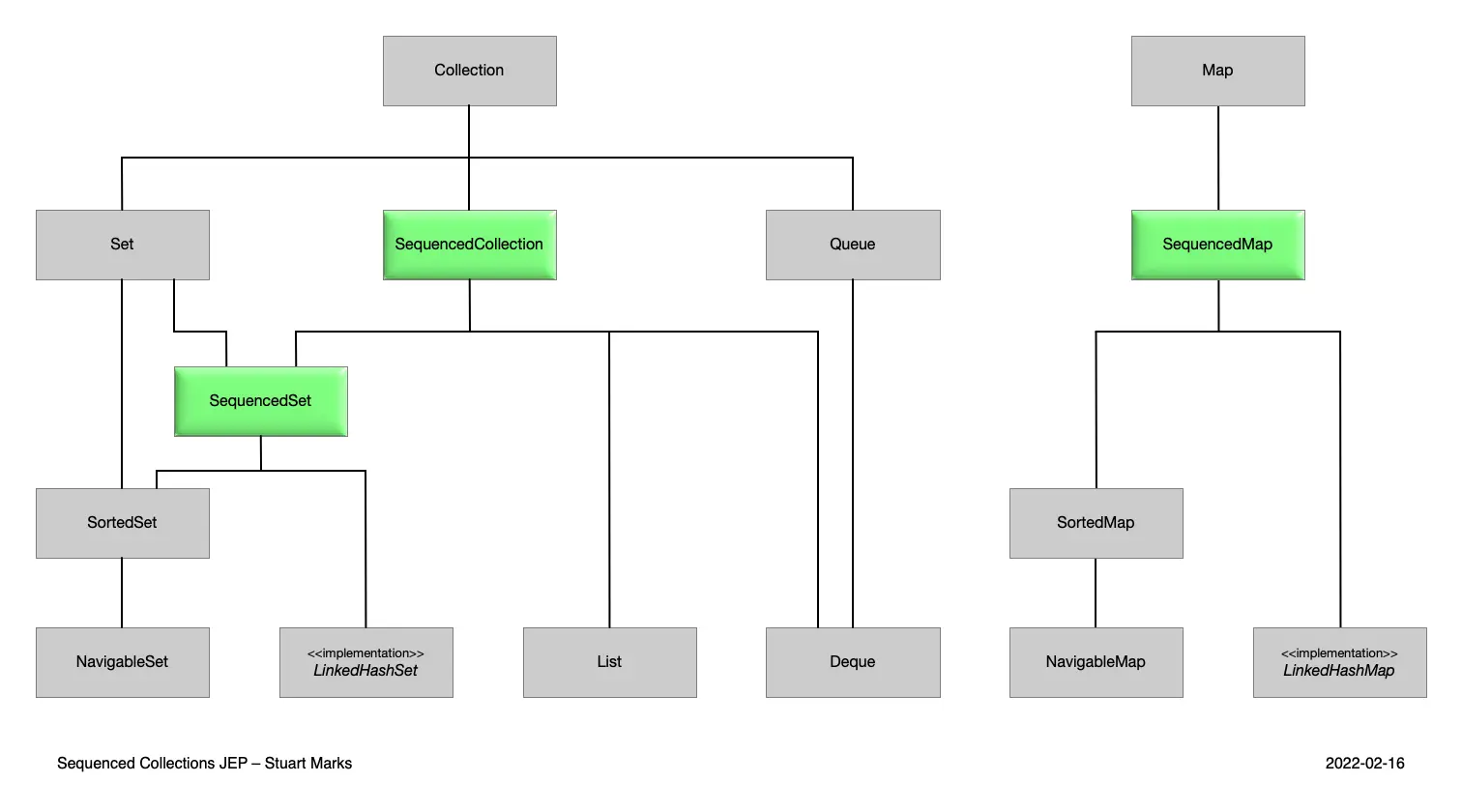 出典:OpenJDK - JEP 431: Sequenced Collections
出典:OpenJDK - JEP 431: Sequenced Collections
継承関係によってダウンキャストが発生する場合もあるかなと思いますが、Listの場合はSequencedCollectionを継承しているのでそのまま新しいメソッドを使うことができます。
Generational ZGC
ZGCはJava 11で導入されたGarbage Collectorですが、Java 21ではGenerational ZGCという機能が追加されました。これはZGCの性能を向上させるために、ZGCのヒープをYoung GenerationとOld Generationに分けることになります。これによって、Young GenerationのGCをより頻繁に行うことができるようになり、Young GenerationのGCの時間を短縮することができ、メモリやCPUのオーバーヘッドを減らすことができるらしいです。
Generational ZGCを使うには以下のように起動オプションを指定します。
java -XX:+UseZGC -XX:+ZGenerational
ただ、新しいGCに関しては公式のドキュメントを参照すると色々と設計や実装について述べていますが、アプリケーションエンジニアの立場としてはそれを使った場合の実際の性能上の利点がどれくらいあるのかが気になるところですね。なので、実際にGenerational ZGCを使った場合の性能についてはこちらの記事が参考になるかと思います。結論としてはまだParallelGCがもっとも性能が良いということになっています。もちろんこれはマシンスペック(特にメモリ)によっても変わってくると思うので、自分の環境で試してみるのが良いかと思います。
Record Patterns
Java 16ではPattern Matchingという機能が導入され、instanceOfで型チェックをした後にキャストするというコードを簡潔に書くことができるようになりました。例えば以下のようなものです。
// Prior to Java 16
if (obj instanceof String) {
String s = (String)obj;
... use s ...
}
// As of Java 16
if (obj instanceof String s) {
... use s ...
}
Java 21ではこのPattern Matchingを、同じくJava 16で導入されたRecordにも適用することができるようになりました。例えば以下のようなコードです。
// As of Java 16
record Point(int x, int y) {}
static void printSum(Object obj) {
if (obj instanceof Point p) {
int x = p.x();
int y = p.y();
System.out.println(x+y);
}
}
// As of Java 21
static void printSum(Object obj) {
if (obj instanceof Point(int x, int y)) {
System.out.println(x+y);
}
}
さらにネストしたRecordにも適用することができます。例えば以下のようなコードも可能です。
static void printXCoordOfUpperLeftPointWithPatterns(Rectangle r) {
if (r instanceof Rectangle(ColoredPoint(Point(var x, var y), var c),
var lr)) {
System.out.println("Upper-left corner: " + x);
}
}
Pattern Matching for switch
Pattern Matchingの改善はswitchにも適用されています。例えば以下のように、switchのcaseにnullを指定することができたり、スマートキャストが使えたり、さらにwhenを使った条件分岐ができるようになりました。
static void testStringEnhanced(String response) {
switch (response) {
case null -> { }
case "y", "Y" -> {
System.out.println("You got it");
}
case "n", "N" -> {
System.out.println("Shame");
}
case String s
when s.equalsIgnoreCase("YES") -> {
System.out.println("You got it");
}
case String s
when s.equalsIgnoreCase("NO") -> {
System.out.println("Shame");
}
case String s -> {
System.out.println("Sorry?");
}
}
}
この改善はEnumにも適用されています。例えば以下のようなコードが可能になりました。
static void exhaustiveSwitchWithBetterEnumSupport(CardClassification c) {
switch (c) {
case Suit.CLUBS -> {
System.out.println("It's clubs");
}
case Suit.DIAMONDS -> {
System.out.println("It's diamonds");
}
case Suit.HEARTS -> {
System.out.println("It's hearts");
}
case Suit.SPADES -> {
System.out.println("It's spades");
}
case Tarot t -> {
System.out.println("It's a tarot");
}
}
}
まだprimitive typeには適用されないのですが、これは今後改善する予定らしいので、また次のバージョンで期待したいところです。
Foreign Fuctions and Memory Access API (Third Preview)
Java 19から導入された機能で、Java runtime外のコードやデータにアクセスできるようなAPIが追加されます。これはJava 21ではThird Previewとして提供されていて、JavaからCやC++のコードを呼び出すことができるようになります。例えば以下のようなコードでCのライブラリを呼び出すことができます。
// 1. Find foreign function on the C library path
Linker linker = Linker.nativeLinker();
SymbolLookup stdlib = linker.defaultLookup();
MethodHandle radixsort = linker.downcallHandle(stdlib.find("radixsort"), ...);
// 2. Allocate on-heap memory to store four strings
String[] javaStrings = { "mouse", "cat", "dog", "car" };
// 3. Use try-with-resources to manage the lifetime of off-heap memory
try (Arena offHeap = Arena.ofConfined()) {
// 4. Allocate a region of off-heap memory to store four pointers
MemorySegment pointers
= offHeap.allocateArray(ValueLayout.ADDRESS, javaStrings.length);
// 5. Copy the strings from on-heap to off-heap
for (int i = 0; i < javaStrings.length; i++) {
MemorySegment cString = offHeap.allocateUtf8String(javaStrings[i]);
pointers.setAtIndex(ValueLayout.ADDRESS, i, cString);
}
// 6. Sort the off-heap data by calling the foreign function
radixsort.invoke(pointers, javaStrings.length, MemorySegment.NULL, '\0');
// 7. Copy the (reordered) strings from off-heap to on-heap
for (int i = 0; i < javaStrings.length; i++) {
MemorySegment cString = pointers.getAtIndex(ValueLayout.ADDRESS, i);
javaStrings[i] = cString.getUtf8String(0);
}
} // 8. All off-heap memory is deallocated here
assert Arrays.equals(javaStrings,
new String[] {"car", "cat", "dog", "mouse"}); // true
今はJavaを使って他の言語で作られたライブラリやアプリケーションを参照する場合、WrapperやRuntimeを利用した形が多いかなと思いますが、これを使うことでより簡単に他の言語のライブラリを呼び出すことができ、アプリケーションのサイズを減らしたり、パフォーマンスを向上させることができるようになるかなと思います。ただ、まだPreviewなので今後変わる可能性があるのと、直接メモリにアクセスするのでメモリリークの可能性があるかなと思いますので、使用時には注意が必要かと思います。
Unnamed Patterns and Variables (Preview)
処理の中で使われてない変数を_で表現することができるようになりました。なので、以下のようなコードが書けるようになります。
// Loop
int acc = 0;
for (Order _ : orders) {
if (acc < LIMIT) {
... acc++ ...
}
}
// Multiple assignment
Queue<Integer> q = ... // x1, y1, z1, x2, y2, z2, ...
while (q.size() >= 3) {
var x = q.remove();
var _ = q.remove();
var _ = q.remove();
... new Point(x, 0) ...
}
// Catch block
String s = ...
try {
int i = Integer.parseInt(s);
... i ...
} catch (NumberFormatException _) {
System.out.println("Bad number: " + s);
}
// try-with-resources
try (var _ = ScopedContext.acquire()) {
... no use of acquired resource ...
}
// Lambda
stream.collect(Collectors.toMap(String::toUpperCase, _ -> "NODATA"))
Virtual threads
Project Loomという名で長い間開発されていた機能です。個人的な意見ですが、Java 21においてもっとも注目されている機能ではないかと思います。既存のマルチスレッドプログラミングでは生成できるスレッドの数において物理的な制約があったのですが、今回の導入される仮想スレッドはそのOSのスレッドをさらに細かく分けて使うことになるので、より多くのスレッドを同時に扱うことができるのが特徴です。
使い方としては既存の物理スレッドと大きく変わるわけではないので、以下のようなコードで使うことができます。
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10_000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
} // executor.close() is called implicitly, and waits
仮想スレッドは実際のOSのスレッドに1:1対応しないので、既存のようにThreadPoolを作成してスレッドの数を制限する必要はほとんどありません。公式でもPoolを使うことをおすすめしないと言っているくらいです。
実際KotlinでJavaの仮想スレッドを利用するようにDispatcherを実装して実験した記事によると、30スレッドのマシンでも100万の 仮想スレッドを作成して処理を行うことができるのがわかります。JVM言語で作成されたサーバーサイドアプリケーションの場合、従来のスレッドモデルではスレッドの数を制限する必要があったので、この仮想スレッドの導入によって、より多くのリクエストを同時に処理することができるようになるかなと思います。
Unnamed Classes and Instance Main Methods (Preview)
関数をトップレベルに定義することができるようになりました。なので、伝統のHello Worldのサンプルは以下のようなコードが書けるようになります。
// Prior to Java 21
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
// As of Java 21
void main() {
System.out.println("Hello, World!");
}
トップレベルの関数やフィールドもUnnamed Classのメンバー扱いとなるので、以下のようなコードも問題なく動きます。
// Method
String greeting() { return "Hello, World!"; }
void main() {
System.out.println(greeting());
}
// Field
String greeting = "Hello, World!";
void main() {
System.out.println(greeting);
}
また、main関数を持つUnnamed Classは以下のように実行することができます。
new Object() {
// the unnamed class's body
}.main();
Scoped Values (Preview)
Webアプリケーションの場合、一つのリクエストに対してはスレッドが割り当てられ、一貫したコンテキストの中で実行されるようにするのが一般的です。ただ、そこでコンテキストをオブジェクトとして扱う場合、既存だと実行される関数の引数として渡す必要があります。例えば以下のようなコードです。
@Override
void handle(Request request, Response response, FrameworkContext context) {
...
var userInfo = readUserInfo(context);
...
}
private UserInfo readUserInfo(FrameworkContext context) {
return (UserInfo)framework.readKey("userInfo", context);
}
または、ThreadLocalを使用して以下のように書くこともできます。
public class Framework {
private final Application application;
public Framework(Application app) { this.application = app; }
private final static ThreadLocal<FrameworkContext> CONTEXT
= new ThreadLocal<>();
void serve(Request request, Response response) {
var context = createContext(request);
CONTEXT.set(context);
Application.handle(request, response);
}
public PersistedObject readKey(String key) {
var context = CONTEXT.get();
var db = getDBConnection(context);
db.readKey(key);
}
}
しかし、ThreadLocalを使う場合は色々と問題があります。まずThreadLocalの値そのものが変更されるということです。そして不要になったThreadLocalの値を適宜削除する必要があったり、オーバーヘッドが発生するということです。
そこでJava 21ではScopedValueというクラスが追加されました。これを使うと以下のようにスレッドあたりの値を設定することができます。
class Framework {
private final static ScopedValue<FrameworkContext> CONTEXT
= ScopedValue.newInstance();
void serve(Request request, Response response) {
var context = createContext(request);
ScopedValue.where(CONTEXT, context)
.run(() -> Application.handle(request, response));
}
public PersistedObject readKey(String key) {
var context = CONTEXT.get();
var db = getDBConnection(context);
db.readKey(key);
}
}
ScopedVlaueにはsetterがないですが、だからと言って他の値を与えられないわけではないです。ThreadLocalとは別のアプローチで、特定の値を渡してrun()関数を実行することができるようになっています。
private static final ScopedValue<String> X = ScopedValue.newInstance();
void foo() {
ScopedValue.where(X, "hello").run(() -> bar());
}
void bar() {
System.out.println(X.get()); // prints hello
ScopedValue.where(X, "goodbye").run(() -> baz());
System.out.println(X.get()); // prints hello
}
void baz() {
System.out.println(X.get()); // prints goodbye
}
このScopedValueはスレッドの実行中にだけ値が保持されないので、ThreadLocalより安全な使い方ができるようになっています。
Vector API (Sixth Incubator)
Java 1.0の時代の配列を扱うVectorとは違って、数値(行列)の計算のためのVector APIが追加されました。基本的に以下のようなことができるようになります。
// Prior to Java 21
void scalarComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
// As of Java 21
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void vectorComputation(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va)
.add(vb.mul(vb))
.neg();
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
一般的なWebアプリケーションではあまり使われることはないかと思いますが、もしこのような計算が必要とされる処理を書く場合、従来のコードよりも高速で並列かもできるということなので、使う場面があるかもしれません。
Deprecate the Windows 32-bit x86 Port for Removal
Windows x86-32のポートがいずれ終わるので、まずはDeprecatedにしてするということです。Virtual Threadが該当のOSだと期待通りの性能向上がなく、32bitに対応する最後のWindowsであるWindows 10が2025年10月にサポート終了となるための対応とされています。
Prepare to Disallow the Dynamic Loading of Agents
Java agentによる動的ロードは、実行中のアプリケーションを変更することも可能です。しかしこのよう機能はアプリケーションの整合性を保証できなくする可能性もあります。そのような問題を防ぐために、将来は動的ロードを禁止し、Java 21ではまず警告を出力します。以下のようなメッセージが出力されることがあります。
WARNING: A {Java,JVM TI} agent has been loaded dynamically (file:/u/bob/agent.jar)
WARNING: If a serviceability tool is in use, please run with -XX:+EnableDynamicAgentLoading to hide this warning
WARNING: If a serviceability tool is not in use, please run with -Djdk.instrument.traceUsage for more information
WARNING: Dynamic loading of agents will be disallowed by default in a future release
このような警告を回避するためにはアプリケーションの実行時に-XX:+EnableDynamicAgentLoadingというオプションを指定する必要があります。
DatadogやJMXなどアプリケーションをモニタリングするためのツールがこのような機能に依存している場合があるので、今後のバージョンを使う際には何か実装の方法が変わるかもしれませんね。
Key Encapsulation Mechanism API
最新の暗号化のアルゴリズムに対応するものです。量子コンピュータでは既存の暗号化アルゴリズムが通用しなくなるという話もあるので、その対応として導入されたものかと思われます(公式でも、 Post-Quantum Cryptography standardization processと述べています)。
新しいアルゴリズムを用いた公開鍵・秘密鍵のペアの生成、カプセル化、カプセルの解除などの機能に対応しています。以下のような使い方となります。
// Receiver side
KeyPairGenerator g = KeyPairGenerator.getInstance("ABC");
KeyPair kp = g.generateKeyPair();
publishKey(kp.getPublic());
// Sender side
KEM kemS = KEM.getInstance("ABC-KEM");
PublicKey pkR = retrieveKey();
ABCKEMParameterSpec specS = new ABCKEMParameterSpec(...);
KEM.Encapsulator e = kemS.newEncapsulator(pkR, specS, null);
KEM.Encapsulated enc = e.encapsulate();
SecretKey secS = enc.key();
sendBytes(enc.encapsulation());
sendBytes(enc.params());
// Receiver side
byte[] em = receiveBytes();
byte[] params = receiveBytes();
KEM kemR = KEM.getInstance("ABC-KEM");
AlgorithmParameters algParams = AlgorithmParameters.getInstance("ABC-KEM");
algParams.init(params);
ABCKEMParameterSpec specR = algParams.getParameterSpec(ABCKEMParameterSpec.class);
KEM.Decapsulator d = kemR.newDecapsulator(kp.getPrivate(), specR);
SecretKey secR = d.decapsulate(em);
Structured Concurrency (Preview)
並列処理をより簡単にするためのAPIです。複数のスレッドで実行される作業の単位を一つのタスクとして扱うことができます。
例えば以下のようなコードがあったとします。userとorderのデータをそれぞれ違うスレッドで取得して、その結果を返す関数です。
Response handle() throws ExecutionException, InterruptedException {
Future<String> user = esvc.submit(() -> findUser());
Future<Integer> order = esvc.submit(() -> fetchOrder());
String theUser = user.get(); // Join findUser
int theOrder = order.get(); // Join fetchOrder
return new Response(theUser, theOrder);
}
上記のコードだと、以下のような問題が考えられます。
- findUser()で例外が発生してもfetchOrder()は実行されてリソースの無駄になる
- handle()を実行しているスレッドがインタラプトされた場合、findUser()とfetchOrder()は実行されたままになる
- findUser()の実行が長すぎる場合、fetchOrder()が失敗してもそれを待つことになる(結果的に失敗)
これらの問題が挙げられてということは、新しいAPIではそれを解決できるということですね。新しいAPIでは上記の問題を、以下のようなコードで解決します。
Response handle() throws ExecutionException, InterruptedException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<String> user = scope.fork(() -> findUser());
Supplier<Integer> order = scope.fork(() -> fetchOrder());
scope.join() // Join both subtasks
.throwIfFailed(); // ... and propagate errors
// Here, both subtasks have succeeded, so compose their results
return new Response(user.get(), order.get());
}
}
StructuredTaskScopeを利用して処理を行う場合、以下のメリットがあります。
- findUser()やfecthOrder()のどちらかが失敗したら、残りの処理はキャンセルされる
- handle()を実行しているスレッドがインタラプトされた場合、findUser()とfetchOrder()はキャンセルされる
- 処理が明確に理解できる
API
今回の新しいAPIに関しては、言語スペックでよく説明されており、新しいJavadocの方でそれぞれのバージョン別にどんなものが追加されたかフィルタしながら確認ができるので、ここではJavadocのリンクだけを貼っておきます。
最後に
いかがだったでしょうか。私はもうJavaでアプリを書くことはほとんどなく、主にKotlinを書いていて、新しいAPIもそこまでコードに影響を与えることはないのですが、それでもJavaの新しいバージョンがリリースされると、なんだか嬉しくなりますね。特にVirtual ThreadのようなAPIはKotlinでも使えるし、Javaで作成されたTomcatやNettyのようなミドルウェアの性能もこれを活用することでさらに性能が上がると思うとありがたいです。他にも追加されるAPIはKotlinとはまた違うアプローチをしているので大変勉強になるなと思いました。
今は仕事でJava 17を使っているのですが、Java 21になったらすぐにでも使いたいと思います。特に来年はKotlinも2.0がリリースされるので、Javaの新機能を活かしてKotlinのビルドもパフォーマンスもさらに向上させていきたいなと思います。
では、また!